architecture_overview
Architecture diagram
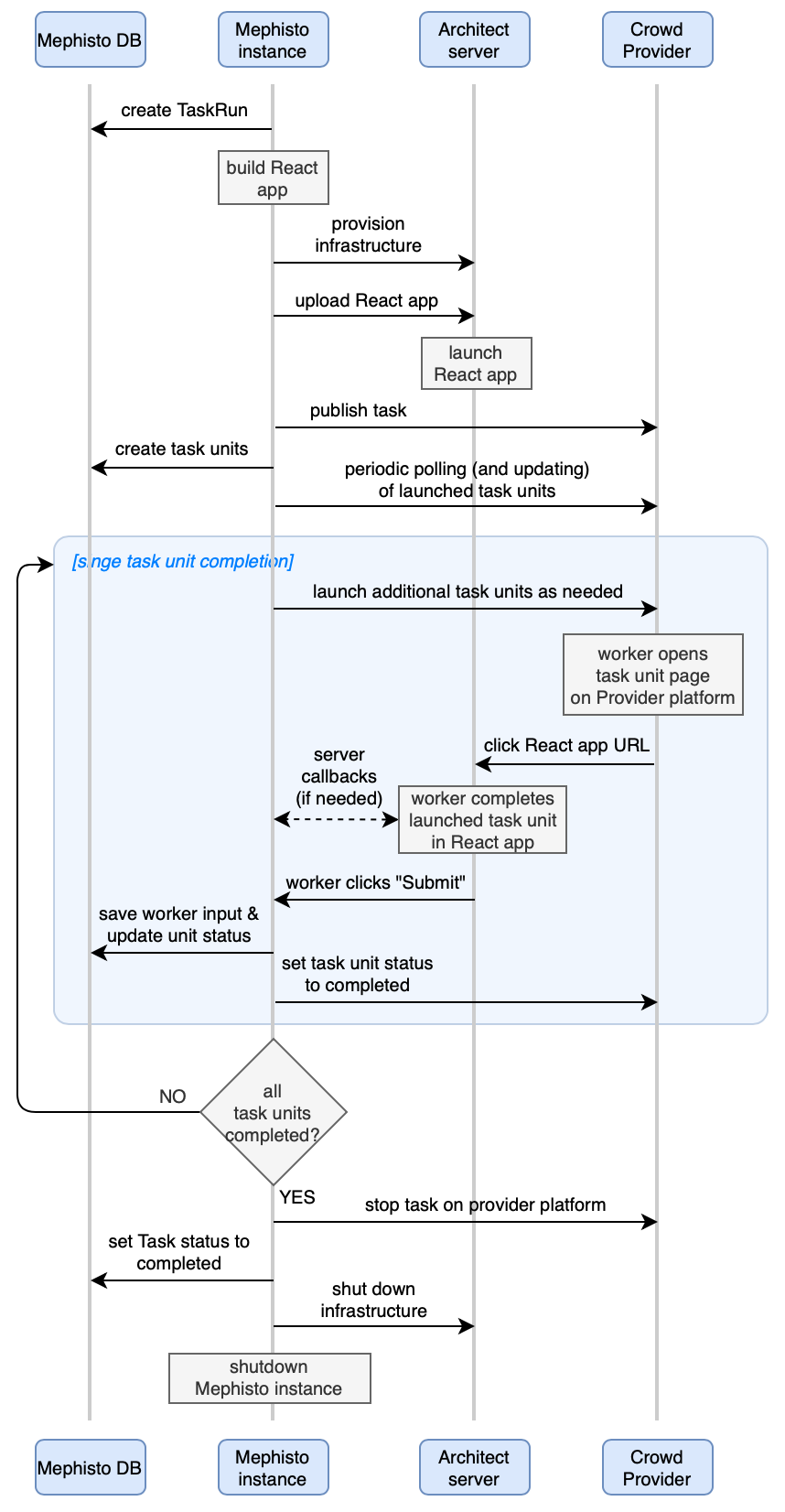
At a high level, Mephisto runs its data collection/annotation tasks as shown in this sequence diagram.
Codebase structure
This is a quick guide over file directories in Mephisto project. Note that some directories include their own README.md file with further details.
data- contain local Mephisto database, provider-specific data stores, and worker input collected during Task runsdocker- dockerization setup for Mephisto projectdocs- content, config, and build forMephisto.aidocslegacy- deprecated doc pagesweb- Docusaurus React app (used to serve doc pages)blog, docs- actual content (pages in Markdown format)other folders- react app build
examples- Mephisto use casesform_composer_demo- FormComposer (FC) examplesdata- JSON configurations for each type of FC setuphydra_configs/conf- YAML configurations for related TaskRunspreview- simple HTML template (used only for Task Preview on Mturk platform)webapp- task's React app containing FCsrc- React code to display FC component (example of using FC plugin in a project)webpack.config.js- webpack config for React app containing FCwebpack.config.remote_procedure.js- webpack config for React app containing FC with remote procedures (e.g. presigned S3 URLs feature)webpack.config.review.js- webpack config for React app displayin read-only task page inside iframe (for TaskReview app)
static_react_task- simple React application (with Onboarding and Screening)static_react_task_with_worker_opinion- simple React application with Worker Opinion widgetsimple_static_task- deprecated example (Mephisto is moving away from HTML templates as its tooling mostly supports React-based tasks)other examples- older Mephisto examples (working, but not the best code structure)
hydra_configs- settings for Hydra (Mephisto's configuration tool)hydra/job_logging- default YAML config for loggingprofile- "drop-in" configs (can be used in any Task by referencing a profile name in Task launch command with a "+" sign)
hydra_plugins- additional tooling for Hydramephisto- main Mephisto project folderabstractions- interface to Mephisto primitives, with subfolders containing their implementations for specific cases (e.g. Parlai Chat, Prolific provider, EC2 architect)client- collection of CLI tools (e.g. launch TaskReview app, launch FormComposer generator, etc)cli.py- contains all supported CLI commands for use withmephisto …command
data_model- classes representing core Mephisto objectsgenerators- Mephisto apps generating code for Task apps based on their configurationform_composer- builds React app for form-based tasks (based on specific provided FC JSON config files), and launches a server to display task units in a browser
operations- part of core Mephisto codereview_app- builds React app for TaskReview, and launches a server to display TaskReview in a browser
outputs- exhaust produced by running the code (logs, database dumps, etc)packages- npm packages (can be used locally, and some are also in npm repo)mephisto-addons- package with FC React component
scripts- command-line utilities for code upkeeptest- All tests (Back-end and Front-end, Unittests and Integration tests)