Mephisto Abstractions
This document seeks to explain the ideas that guided the creation of Mephisto. It will speak about the broad categories of how Mephisto works and how these parts are supposed to play together. It speaks a lot about the design goals of the Mephisto architecture. It isn't a perfect 1:1 representation of how the code is organized at the moment, but rather the ideal we were striving to reach. Understanding these ideals makes it easier to understand Mephisto, both for usage and for joining in on development.
At the highest level, the Mephisto architecture is split into three primary sections:
- The Data Model, which attempts to capture the required state for crowdsourcing tasks from the short through the long term, but at a conceptual level that should allow it to work for all crowdsourcing tasks.
- The Core Abstractions, which attempt to encapsulate all of the parts of crowdsourcing that may frequently change, such as where you find workers, where you run the task, and the task itself.
- The Operations Layer, which comprises a number of classes and utilities that operate common crowdsourcing task flows. This includes launching and monitoring tasks, reviewing incoming data, etc, but generalized by the APIs in the previous layers.
The below sections will give breakdowns on how each of these work and interact.
Data Model
The data model comprises all of the 'unchanging' parts of a crowdsourcing workflow that we believe are 'atomic'. After all, is it possible to have a "crowdsourcing" task without workers? Or without a task to be done? It's important to discuss them first as the rest of Mephisto depends on them. Below are the major classes to consider, relation flows read from top down.
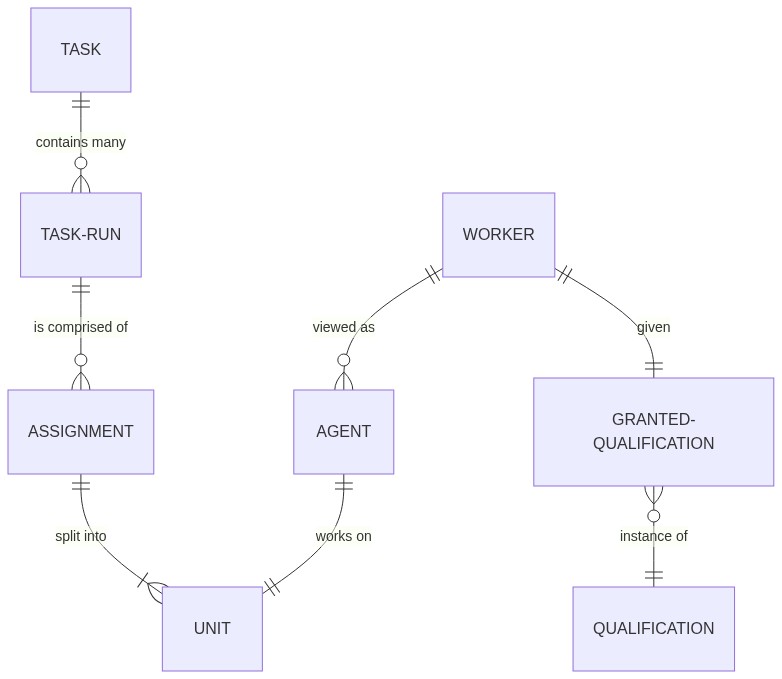
We can break this up into three categories, the elements related to Runs of a task, those related to the actual Assignments in a task run, and the context required to support Worker logic. Everything in the data model is persisted inside of the MephistoDB, such that other processes can examine the status of tasks, view worker behavior, or access the information long after there is no active process running a crowdsourcing task.
Runs
Three primary classes talk about the concept of runs - namely the Project, Task, and TaskRun. They are containers for work at varying levels of similarity.
Tasks
To speak about what the Task class is for, first let's define a Task as a single type of work that you want to collect, and may do so in one or many chunks. In general, you'd want everything in a Task to be something that could be reviewed at the same time, and as such it should share similar context.
Annotate [these] images would be an example of a Task, as would Translate [these] sentences into [language]. Each of these could be extended, for example by giving multiple (similar) annotation types or translating into many different languages. These two tasks though could not reasonably be combined into one Task though, as they are using different context.
Methods of the Task class surround being able to consolidate information about a specific Task, and the task class is uniquely indexed by the task_name property.
Task Runs
A task run can be thought of as part of running an overall task. So, if you wanted to annotate a set of images, but could only do it in parts, each of those parts would be a TaskRun of the image annotation Task that you are working on. Each TaskRun is provided its own set of configuration, and as such your Task to translate some number of sentences into different languages may have a TaskRun that asks workers to translate to Spanish while another TaskRun asks workers to translate the same sentences to French.
For a concrete example, if your original Task was to Annotate 100 images, you could split it into one task run to annotate 50 of them, and two more that annotate 25 each. You may even find out later on that there are 25 extra related images to do, and launch a task run that's still part of the original Task for those as well.
The TaskRun class itself is responsible for being able to report on the status of all of the work being done within, as well as be able to point to Assignments to work on that haven't been completed yet.
Projects
While we can think of a TaskRun as a component of a Task, it's also useful to think of a Task as a component of a Project. The goal behind a Project is to collect analysis information about multiple tasks that aren't similar enough to be combined, but are part of some larger objective. That is to say, you can't create an interface that allows the subtasks of a project to be completed together, but the subtasks are still related.
Projects can be useful to aggregate information about those subtasks in one place, such that they may be utilized in positive ways. Here is where you may be able to find the total budget of a larger group of work, or determine a set of workers with high approval rates for this work. You could also use a Project more for archival reasons, marking where you can free up some disk space once the work is final.
Note: The
Projectclass is largely un-implemented at this point, and its convenience methods are likely to come in future releases.
Assignments
Where the Task classes are used to define big pieces of work that need to be done, the Assignment and Unit classes are used to drill down on the work that you'll actually be showing to a worker. Here, a TaskRun is comprised of one or more Assignment's, and an Assignment is comprised of one or more Unit's. The goal of this separation is to make different types of assignment-unit breakdowns valid, such as cooperation or consensus.
Assignment
An Assignment can be thought of the minimal subgoal of a given Task. If your Task is to Annotate 100 images, one such subgoal could be to Annotate 1 image. It may be appropriate to batch these, such that the assignment is actually to Annotate these 5 images, but the goal here is to ensure that an Assignment represents a reasonable amount of work to accomplish, but small enough to be reviewed as a whole. Continuing our earlier example, you may launch a task run to annotate 50 images, where each assignment is to annotate 5 images. For these parameters Mephisto will create 10 such assignments.
In some cases, an Assignment may relate to something that needs to be done by multiple workers at once, such as a cooperative task. In other cases, an Assignment may relate to wanting multiple different workers to attempt the same task in order to get consensus. We refer to this as a task being concurrent or not. In either case, however, Mephisto will prevent any given Worker from participating in any Assignment more than once.
Unit
The Unit is the smallest bit of work that is part of a task, in that it comprises a single worker's contribution to that task. It has the required information for initializing a specific instance of work to the worker, and is responsible for having up-to-date information about the real-life status of that work.
Some Assignment's may have just one Unit, should the task be something that can be completable by just one worker and only needs completing once. Some cooperative Assignment's, like a conversation, may be comprised of two (or more) Unit's, each representing one worker's place in the conversation. You can also have two (or more) Unit's for a task that is completed by one worker at a time, wherein both workers will do the same job so that you can get a consensus from multiple workers.
Workers
In this section we discuss workers and their qualifications. The Worker and Agent classes specifically refer to a long-term worker and a worker's specific work on a single Unit respectively. The Qualification class refers to a kind of qualification that a Worker can get, and they are received in the form of a GrantedQualification. The goal for Mephisto's interaction with workers is to keep long-term statistics for individual workers, keep data for specific Unit's organized, and ensure worker eligibility for tasks where possible.
Worker
The Mephisto Worker object keeps track of a specific person after they've interacted with Mephisto. The Worker class is able to track overall pay, acceptance rates, and other trends based on the data that is linked to it. A Worker can also be granted qualifications. Mephisto uses the Worker class primarily to determine eligibility for specific Unit's, and it exposes other functions as helpers for analysis.
Agent
The Agent object can be thought of as an instance of a Worker paired to a specific Unit, in that it tracks the work of the human on the other end as they complete the Unit. It is responsible for tracking the state of the work done, as well as saving the data associated with the work. A Worker that continues to do tasks will end up having as many Agent's as the number of Assignment's they have worked on (as a worker may only contribute to one Unit per Assignment max).
Qualifications
Mephisto Users are able to create custom Qualification's for anything that they may want to partition their Worker's with, and grant them either manually or programatically. Granting a qualification creates a GrantedQualification in the database with the value of the qualification granted. These are later used to determine worker eligibility on tasks when a worker accepts a Mephisto assignment. If the crowd provider allows, they can even be used to prevent the provider from surfacing work to ineligible workers.
Core Abstractions
There are three main abstractions for Mephisto that comprise differences in running crowdsourcing tasks. They are as follows:
- Blueprints - these contain task-specific logic, and can be seen as generalized 'proctors' for a task. When provided configuration parameters, they return materials about how the task should look, who works on it, and how data is saved.
- Architects - these provide logic that actually allows an external entity to be communicating with the Mephisto backend. Given configuration parameters, they provide methods for setting up servers and communication protocols.
- CrowdProviders - these provide a generalized API for dealing with external crowdsourcing providers, wiring primary actions one may want to accomplish up with an external service.
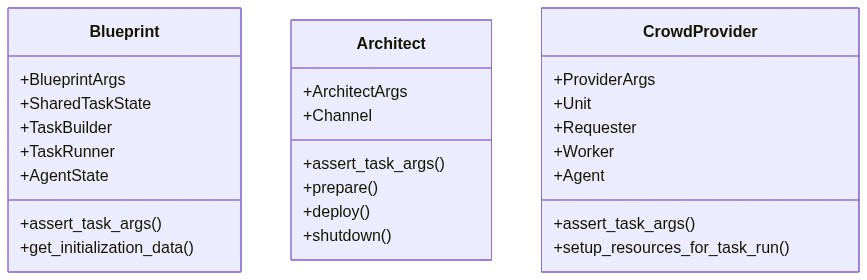
Each of these classes can be considered generalizations that can be configured for usage in specific instances. As such, each of these classes provides a list of parameters that are used to configure their behaviors, and subclasses can provide additional parameters for additional specification. No Blueprint should only work for one specific task, but it should be a blueprint from which many similar tasks can be built.
The classes are all expected to provide an Args class, which is a dataclass that we can use as a structured config alongside Hydra to populate configuration. It should also define an assert_task_args method, which ensures that given a set of configuration, a run with that particular configuration will not fail to execute for any configuration related reasons.
There's also the abstraction of the MephistoDB, which defines the data operations that Mephisto requires to operate properly. If a specific setup requires specialized data handling, any class implementing this interface could stand in for it.
Blueprints
The blueprints contain all of the related code required to set up a task run. Blueprints may follow a hierarchical structure, in that general functionality can be written into abstract blueprints (which are powerful but perhaps hard to configure) and then downstream blueprints may have more configuration control but less breadth. Much of this can actually require significant overhead, so we've created additional abstract classes that a blueprint must link to an implementation for. These are listed below:
BlueprintArgs
These define the specific arguments for configuring a blueprint. Some base arguments relevant to all blueprints are provided already, and classes that override BlueprintArgs can add anything else they want.
SharedTaskState
Some tasks require additional state that cannot be considered static configuration, such as validation functions for accurate completion of a task, or a counter for the number of tasks completed in a run so far, or any other python state that multiple different assignments may be interested in accessing or altering. This class is for the edge cases that need something more than static configuration, and is created as a singleton shared between all tasks in a TaskRun.
TaskBuilder
All tasks need to have some kind of frontend interface for workers to interact with. The TaskBuilder defines hooks for points in setup where this frontend is compiled and built (or located and confirmed alive), and implementations for a specific Blueprint should use this part of the lifecycle to set up these things.
TaskRunner
Likewise, all tasks need to have some kind of backend logic that dictates the kind of information we intend to receive. For simple 'static' tasks where we give the worker some info and they give us their work, this may be just a single exchange, however more complicated tasks can put any other kind of difficult flow control here.
AgentState
As different tasks will save different data, Blueprints need a way to specify what kind of data is being saved. The AgentState is responsible for parsing out the required information that will need to be saved during a task, viewed during review, and exported during a final compilation. It receives both the initial information given to the worker, as well as every action packet sent to or by the worker.
Onboarding
Blueprints also provide simple hooks for "onboarding" assignments, which can be considered as assignments that a worker must complete in order to qualify for the real thing. These hooks are added to the TaskRunner and AgentState to provide a way to set the flow for onboarding, what is saved, and how the work is evaluated.
Architects
Architect's contain the logic surrounding deploying a server that workers will be able to access. In many cases Mephisto is being run on compute clusters that aren't directly addressable, or in different configurations between collaborators. Mephisto should be able to run a task from start to finish regardless of the server configuration a user would like to use, and Architect's provide this capability.
The Architect class is responsible for providing Mephisto with lifecycle functions for preparing, deploying, and shutting down a given server. It's also responsible with providing access to the user via a Channel, which defines an interface of callbacks for incoming messages and a function for outgoing messages.
You may pick from any of the existing architects that work with your setup, or can create/customize your own if none fit your server configuration.
CrowdProviders
The CrowdProvider abstraction is responsible for standardizing Mephisto's interaction with external crowds. As such, the methods within a CrowdProvider are used to wrap some methods for using external crowd APIs (such as botocore for MTurk) in a format that Mephisto can use in a more general way. Much of the registration process for workers, alongside the process for getting the current status of work requires interfacing with the external APIs, and as such some of the classes provided in the Data Model need to be wrapped in a crowd layer. As such a CrowdProvider must provide a class for the following:
Unit- Mephisto needs to be able to publish work to the external platforms, get the status of published work, cancel jobs that should no longer be completed. Further, users may want an opportunity to map between external task ids and Mephisto unit ids more directly.Worker- Mephisto needs to register a worker given the information that a crowd provider will give about their identity. It also needs to know how to grant qualifications for a given worker, or block them from working on tasks.Requester- Mephisto needs an interface for making requests to the crowd provider, usually in the form of a registered account. This class contains methods for registering credentials with Mephisto, andRequester's are then used as the identity launching a task.Agent- Mephisto needs to know how to check on the status of work on a particular unit, and later needs to know how to review and compensate a worker for work done. We also may need to be able to tell a crowd provider that a worker has successfully completed their work.
Operations Layer
The above components provide an abstraction around the bare-bones components involved in a crowdsourcing task. The operations layer is responsible for providing simple functions and knobs that can then execute common crowdsourcing workflows from user scripts. To this end, we have the Operator, ClientIOHandler, WorkerPool and TaskLauncher classes. The latter three provide simple interfaces for the Operator to interact with the lower layers, and the Operator provides the highest level operational functions for Mephisto.
Supervisor
NOTE: The Supervisor has been deprecated in 1.0, and this doc doesn't yet reflect the functionality change. Nowadays the ClientIOHandler and WorkerPool cover the functionality it used to.
The goal of the supervisor is to manage the process of delegating work to specific agents, and to check in on how the agents are doing on that work. As such it receives a LiveTaskRun (pairing of Architect, Blueprint, and CrowdProvider) that it is supposed to have workers complete, and it is responsible for listening in to actions coming from the server and translating those into the process of assigning, monitoring, and marking the status of tasks. Another way to think of it is that it's responsible for mapping agent actions as received by the Architect's server to state changes enacted via the Blueprint and the CrowdProvider. Two example flows are below:
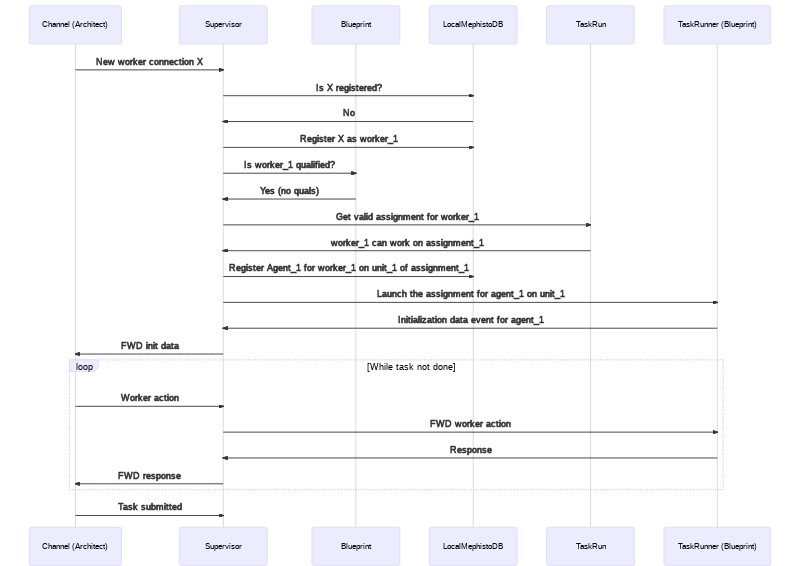
This example demonstrates a simple one person task completed normally by a worker new to the Mephisto system.
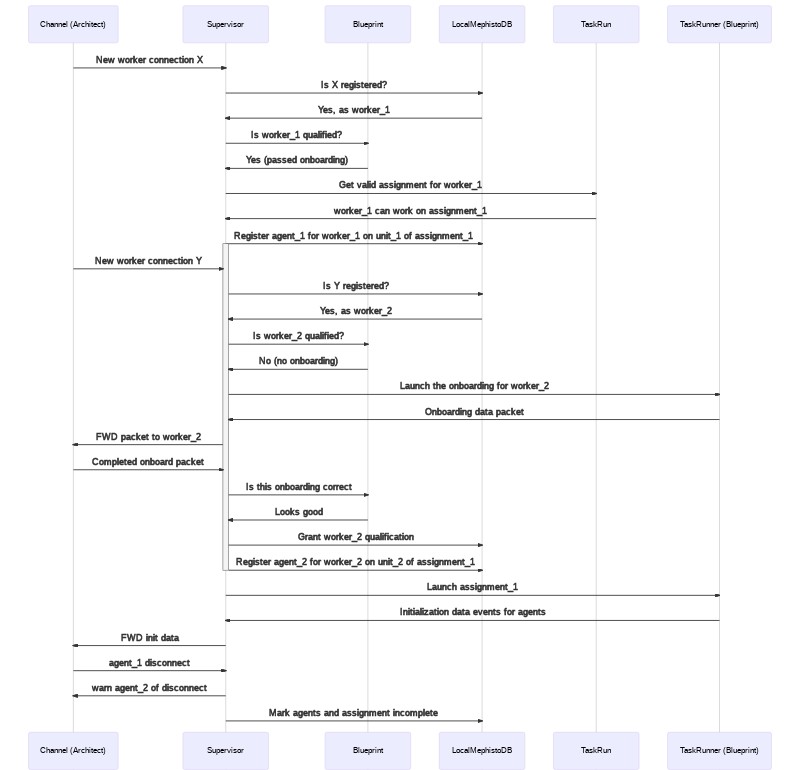
This example shows a more complicated scenario, where two workers both need to work on the task co-operatively, however the first hasn't completed onboarding yet and then partway through the task one worker disconnects.
Task Launcher
The goal of the task launcher is to handle the interactions required to make the Assignments desired by the user public on the CrowdProvider. This requires some constant work, as a user may specify that they only want a specific number of concurrent Assignment's running at once (due to compute constraints), and as such they must be launched over time. It also may be the case that the user doesn't know exactly how many Assignment's are needed at the onset, as it may be possible to automatically evaluate and re-queue some work that is completed.
Operator
Finally, the operator is responsible for connecting all of the components together to provide single-function interfaces into Mephisto functionality. At the moment it's only able to operate the deploy flow, however we'd also like to add review and package functionality in the future.
The core responsibility of the Operator is to, given a task to deploy and configuration for running that task, validate that the task can be run, initialize the relevant instances of the Core Abstractions, register these with a Supervisor and TaskLauncher, and then observe the status of the whole system until the run is complete.
DataBrowser
As the Mephisto data model is all stored to disk, we also provide a MephistoDataBrowser class that has common methods used in other parts of the workflow, such as reviewing work and analyzing trends.